Learn the most influential and useful Algorithms


Learning algorithms is a journey filled with mixed emotions. For many, it evokes a sense of accomplishment while also reminding us of the time spent grappling with complex concepts. However, the rewards are immense—a strong understanding of algorithms is essential for any software developer or engineer, as it significantly enhances problem-solving skills and mental agility. If you're ready to embark on this journey or looking for additional resources to deepen your understanding, this guide will introduce you to some of the most influential and useful algorithms in computer science. Use this guide for reference and make sure you understand the complete process to effectively apply an algorithm to a problem in data structures and algorithms (DSA).
Algorithms We are going to Discuss about :
These algorithms are used for a variety of applications and are strongly encouraged by experts.
1. Sieve of Eratosthenes:
The Sieve of Eratosthenes is a classic algorithm for finding all prime numbers up to a specified integer .
History and Background:
The algorithm is named after Eratosthenes of Cyrene, a Greek mathematician and scholar who lived from approximately 276 to 194 BCE.Eratosthenes was a prominent figure in ancient Greece, known for his work in mathematics, astronomy, and geography. He was the chief librarian at the Library of Alexandria.
Where It Is Used
1. Identification of Prime Numbers:
- Number Theory: The Sieve of Eratosthenes is primarily used to identify all prime numbers up to a specified integer. It's a foundational tool in number theory, which studies the properties and relationships of numbers.
2. Mathematical Software:
- Algorithmic Libraries: The Sieve of Eratosthenes is commonly employed in mathematical software and libraries to generate prime numbers as a preprocessing step. It's used in more complex algorithms and computations where a list of primes is required.
3. Complexity Analysis:
- Benchmarking Algorithms: This algorithm is often used as a benchmark for analyzing the efficiency of other algorithms, particularly those dealing with prime numbers or integer sequences. It provides a standard against which the performance of more advanced algorithms can be measured.
Understanding the Algorithm :
This algorithm is used to find the prime numbers with in the range .
let us say we have to find the prime numbers below hunderd.
1 List down all the numbers .
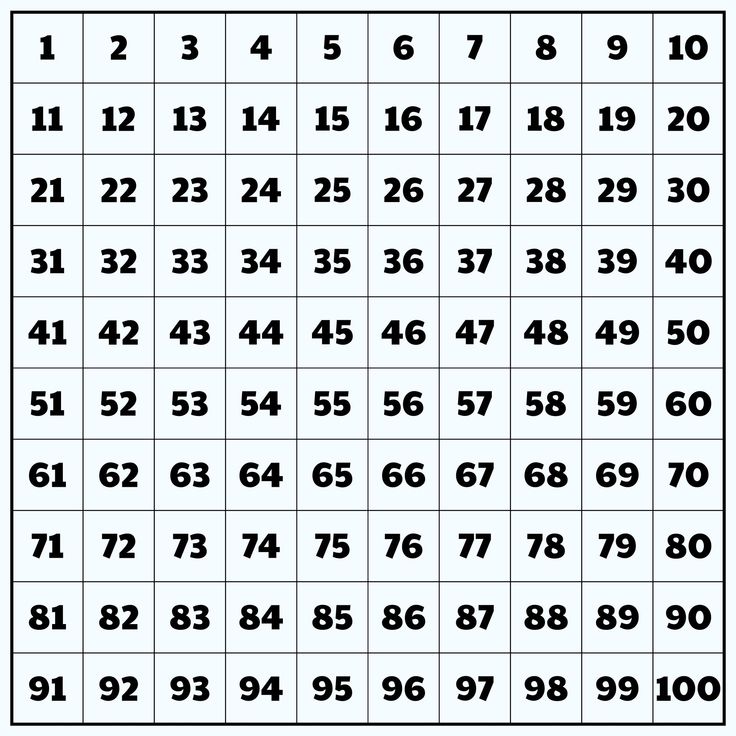
as 1 is neither prime nor composite we can remove it .
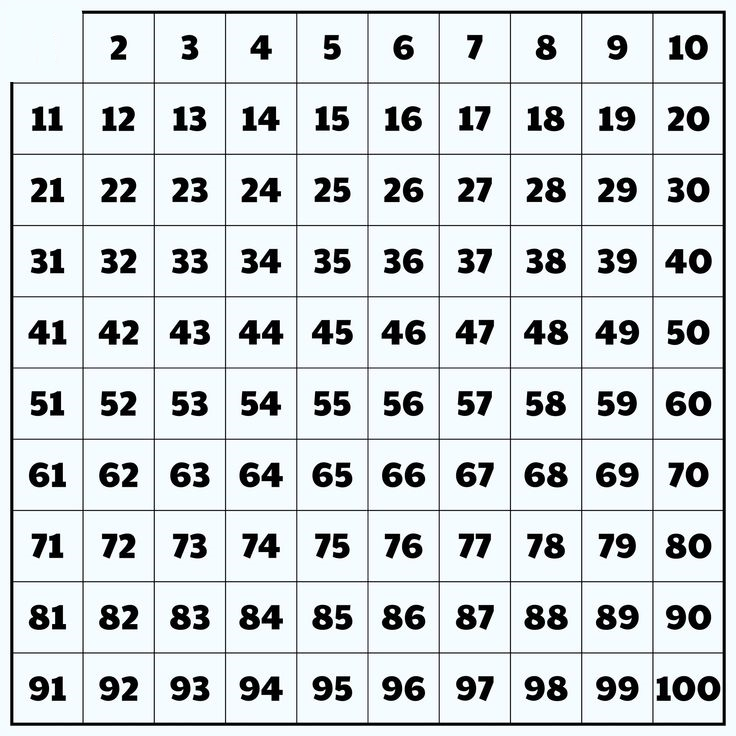
2. Now select the first unmarked element that is 2 (always)and store it in a primenumbers array. And mark every possible number which is divisible by 2 within the range . Becuase as they are divided by 2 they are considered as composite numbers (common factor not equal 1).
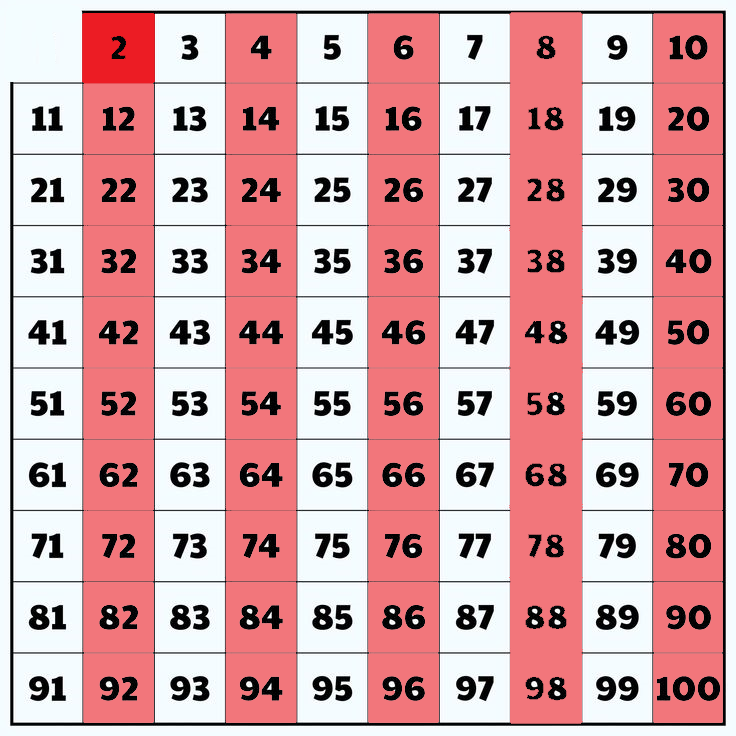
Primenumbers = [2]
3. Similarly , Now select the next unmarked element and push it into the array and mark the multiples of that particular number.
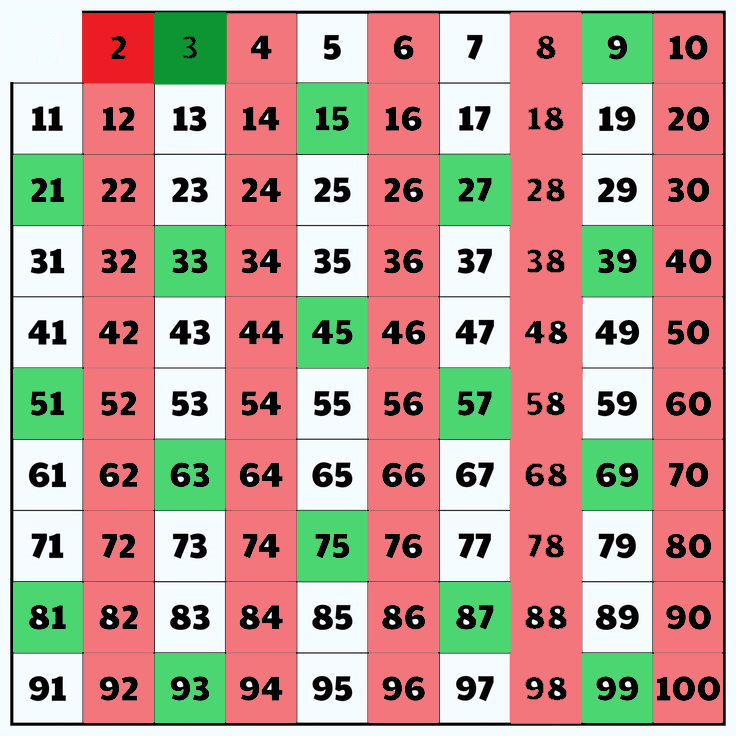
Primenumbers=[2,3]
Now , Repeat these steps until every element is traversed in the range given .
1.shift to the next unmarked element .
2.push the element into the Primenumber array and mark the element.
3.mark all the multiples of the given number element.
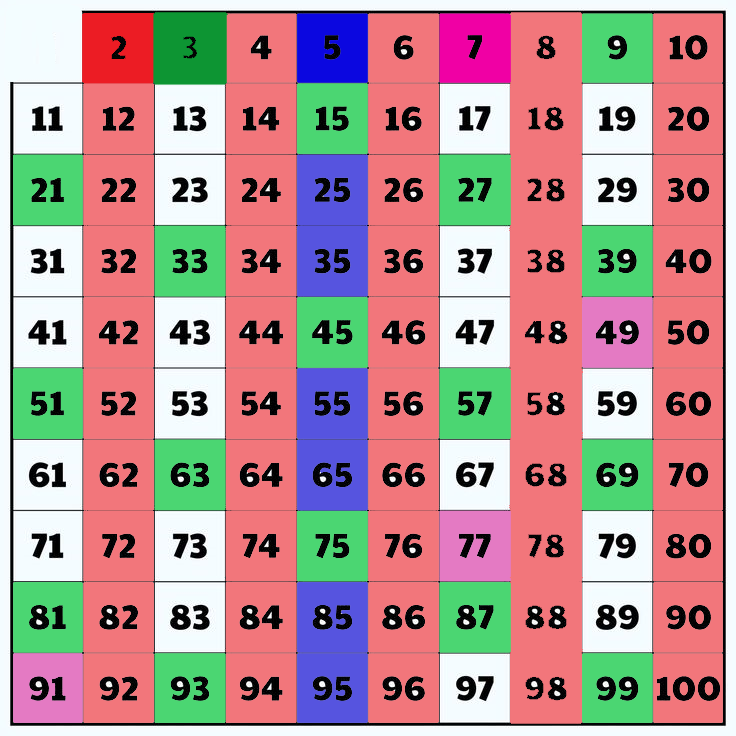
Primenumbers=[2,3,5,7]
Now,after traversing to all the elements in the range , push the unmarked elements into the Primenumbers.

Primenumbers=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89 , 97.]
In this Way we can find the prime numbers for a given range using Sieve of Eratosthenes Theorem.
code
#include <iostream>
#include <vector>
using namespace std;
void sieve_of_eratosthenes(int n) {
// Create a boolean array "prime[0..n]" and initialize all entries as true
vector<bool> prime(n + 1, true);
// 0 and 1 are not prime numbers
prime[0] = prime[1] = false;
for (int p = 2; p * p <= n; ++p) {
// If prime[p] is not changed, then it is a prime
if (prime[p] == true) {
// Updating all multiples of p to false indicating not prime
for (int i = p * p; i <= n; i += p) {
prime[i] = false;
}
}
}
// Print all prime numbers
for (int p = 2; p <= n; ++p) {
if (prime[p]) {
cout << p << " ";
}
}
cout << endl;
}
int main() {
int n;
cout << "Enter the limit: ";
cin >> n;
sieve_of_eratosthenes(n);
return 0;
}
2.Dutch national flag Theorem:
The Dutch National Flag algorithm, also known as DNF, is an efficient sorting algorithm specifically designed to sort an array containing three distinct values. This algorithm was proposed by Edsger Dijkstra, a Dutch computer scientist.
History and Background:
The algorithm gets its name from the Dutch national flag, which consists of three colors: red, white, and blue. Dijkstra designed this algorithm in 1976 to demonstrate a problem where arranging these three colors in the correct order parallels the task of sorting three distinct values.
Where It Is Used
1. Array Sorting:
- Specific Value Sorting: Commonly used in scenarios where an array needs to be sorted with exactly three distinct values.
- Partition in QuickSort: Used as a partitioning scheme in the QuickSort algorithm.
2. Memory Management:
- Memory Defragmentation: Applied in memory management systems to organize memory blocks of different types.
3. Image Processing:
- Pixel Sorting: Used in image processing where pixels need to be categorized into three distinct groups.
Understanding the Algorithm:
Let's understand this with a simple example where we need to sort an array containing only 0s, 1s, and 2s.
Step 1: Initialization of Pointers
- low pointer (low): Points to the leftmost position (index 0)
- Represents the boundary of the 0s section
- All elements before low are guaranteed to be 0s
- mid pointer (mid): Used for iteration (starts at index 0)
- Current element being examined
- All elements between low and mid-1 are guaranteed to be 1s
- high pointer (high): Points to the rightmost position (index n-1)
- Represents the boundary of the 2s section
- All elements after high are guaranteed to be 2s
Example array: [0, 1, 2, 0, 1, 2] Initial state: low = 0, mid = 0, high = 5
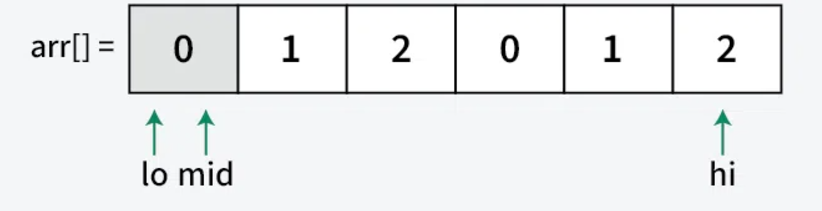
Step 2: Partitioning Process The array is divided into four sections:
- [0 to low-1]: Contains all 0s
- [low to mid-1]: Contains all 1s
- [mid to high]: Unknown/unsorted elements
- [high+1 to n-1]: Contains all 2s
Step 3: Sorting Process For each element arr[mid], we have three cases:
- When arr[mid] = 0:
- Swap arr[low] with arr[mid]
- Increment both low and mid
- This moves 0 to the left section
- Example: [0,1,2] → [0,1,2] (No change)
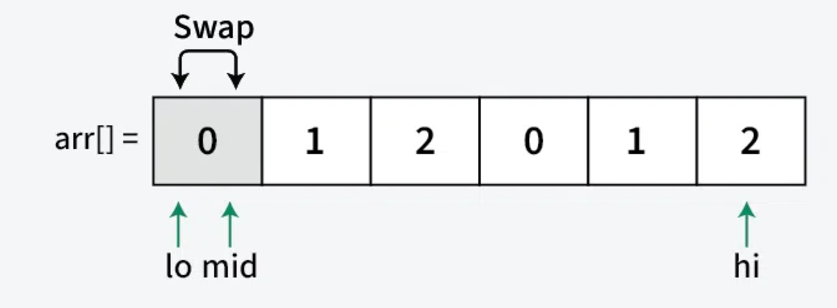
- When arr[mid] = 1:
- Leave element as is
- Just increment mid
- 1s naturally accumulate in middle
- Example: [0,1,2] → [0,1,2] (No change)
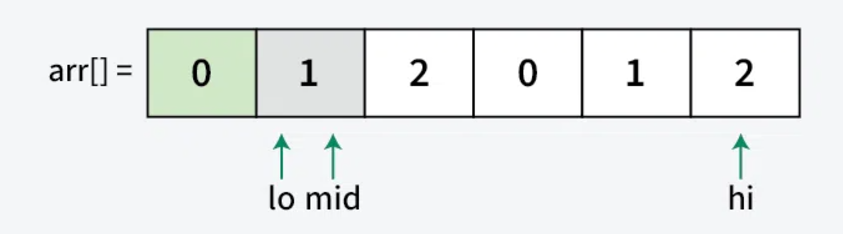
- When arr[mid] = 2:
- Swap arr[mid] with arr[high]
- Decrement high
- This moves 2 to the right section
- Example: [0,1,2] → [0,1,2]

Now Repeat the above steps for yourself as a practice - take reference from below images
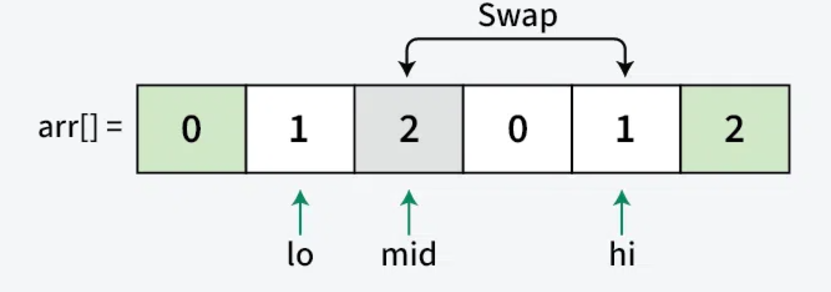
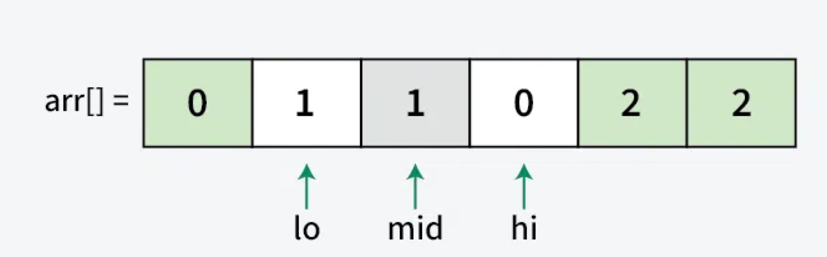
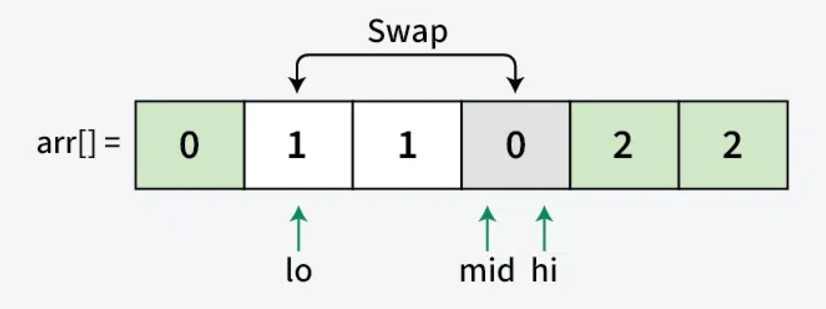
Step 4: Termination
- Algorithm continues until mid pointer crosses high pointer
- At this point, array is fully partitioned:
- All 0s are at the beginning
- All 1s are in the middle
- All 2s are at the end
Example final state: [0,0,1,1,2,2]
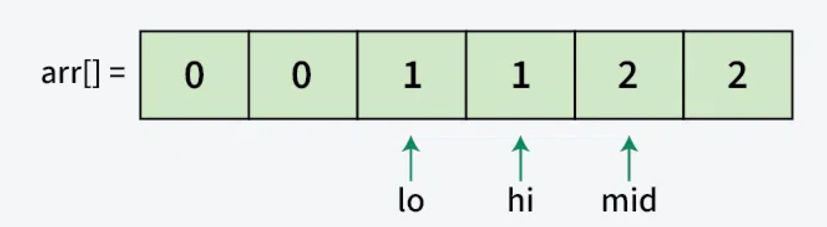
Time and Space Complexity
- Time Complexity: O(n) - Single pass through array
- Space Complexity: O(1) - In-place sorting
- Stability: Not stable (relative order of equal elements may change)
Code
#include <iostream>
#include <vector>
using namespace std;
void dutchNationalFlag(vector<int>& arr) {
int low = 0;
int mid = 0;
int high = arr.size() - 1;
while (mid <= high) {
switch (arr[mid]) {
case 0:
swap(arr[low], arr[mid]);
low++;
mid++;
break;
case 1:
mid++;
break;
case 2:
swap(arr[mid], arr[high]);
high--;
break;
}
}
}
int main() {
vector<int> arr = {2, 0, 1, 2, 1, 0, 2, 1, 0};
cout << "Original array: ";
for (int num : arr) cout << num << " ";
dutchNationalFlag(arr);
cout << "\nSorted array: ";
for (int num : arr) cout << num << " ";
return 0;
}========
title: "Learn the most influential and useful Algorithms" description: "A guide to learn and experience the Algorithms for Various appliactions." image: "../../../packages/articles/featured.png" publishedAt: "2024-09-06" updatedAt: "2024-09-07" author: "Attada Sai Praharsha" username: "attada-sai-praharsha" isPublished: true tags:
- DSA
Learning algorithms is a journey filled with mixed emotions. For many, it evokes a sense of accomplishment while also reminding us of the time spent grappling with complex concepts. However, the rewards are immense—a strong understanding of algorithms is essential for any software developer or engineer, as it significantly enhances problem-solving skills and mental agility. If you're ready to embark on this journey or looking for additional resources to deepen your understanding, this guide will introduce you to some of the most influential and useful algorithms in computer science. Use this guide for reference and make sure you understand the complete process to effectively apply an algorithm to a problem in data structures and algorithms (DSA).
Algorithms We are going to Discuss about :
These algorithms are used for a variety of applications and are strongly encouraged by experts.
1. Sieve of Eratosthenes:
The Sieve of Eratosthenes is a classic algorithm for finding all prime numbers up to a specified integer .
History and Background:
The algorithm is named after Eratosthenes of Cyrene, a Greek mathematician and scholar who lived from approximately 276 to 194 BCE.Eratosthenes was a prominent figure in ancient Greece, known for his work in mathematics, astronomy, and geography. He was the chief librarian at the Library of Alexandria.
Where It Is Used
1. Identification of Prime Numbers:
- Number Theory: The Sieve of Eratosthenes is primarily used to identify all prime numbers up to a specified integer. It's a foundational tool in number theory, which studies the properties and relationships of numbers.
2. Mathematical Software:
- Algorithmic Libraries: The Sieve of Eratosthenes is commonly employed in mathematical software and libraries to generate prime numbers as a preprocessing step. It's used in more complex algorithms and computations where a list of primes is required.
3. Complexity Analysis:
- Benchmarking Algorithms: This algorithm is often used as a benchmark for analyzing the efficiency of other algorithms, particularly those dealing with prime numbers or integer sequences. It provides a standard against which the performance of more advanced algorithms can be measured.
Understanding the Algorithm :
This algorithm is used to find the prime numbers with in the range .
let us say we have to find the prime numbers below hunderd.
1 List down all the numbers .
as 1 is neither prime nor composite we can remove it .
2. Now select the first unmarked element that is 2 (always)and store it in a primenumbers array. And mark every possible number which is divisible by 2 within the range . Becuase as they are divided by 2 they are considered as composite numbers (common factor not equal 1).
Primenumbers = [2]
3. Similarly , Now select the next unmarked element and push it into the array and mark the multiples of that particular number.
Primenumbers=[2,3]
Now , Repeat these steps until every element is traversed in the range given .
1.shift to the next unmarked element .
2.push the element into the Primenumber array and mark the element.
3.mark all the multiples of the given number element.
Primenumbers=[2,3,5,7]
Now,after traversing to all the elements in the range , push the unmarked elements into the Primenumbers.
Primenumbers=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89 , 97.]
In this Way we can find the prime numbers for a given range using Sieve of Eratosthenes Theorem.
code
#include <iostream>
#include <vector>
using namespace std;
void sieve_of_eratosthenes(int n) {
// Create a boolean array "prime[0..n]" and initialize all entries as true
vector<bool> prime(n + 1, true);
// 0 and 1 are not prime numbers
prime[0] = prime[1] = false;
for (int p = 2; p * p <= n; ++p) {
// If prime[p] is not changed, then it is a prime
if (prime[p] == true) {
// Updating all multiples of p to false indicating not prime
for (int i = p * p; i <= n; i += p) {
prime[i] = false;
}
}
}
// Print all prime numbers
for (int p = 2; p <= n; ++p) {
if (prime[p]) {
cout << p << " ";
}
}
cout << endl;
}
int main() {
int n;
cout << "Enter the limit: ";
cin >> n;
sieve_of_eratosthenes(n);
return 0;
}
2.Dutch national flag Theorem:
The Dutch National Flag algorithm, also known as DNF, is an efficient sorting algorithm specifically designed to sort an array containing three distinct values. This algorithm was proposed by Edsger Dijkstra, a Dutch computer scientist.
History and Background:
The algorithm gets its name from the Dutch national flag, which consists of three colors: red, white, and blue. Dijkstra designed this algorithm in 1976 to demonstrate a problem where arranging these three colors in the correct order parallels the task of sorting three distinct values.
Where It Is Used
1. Array Sorting:
- Specific Value Sorting: Commonly used in scenarios where an array needs to be sorted with exactly three distinct values.
- Partition in QuickSort: Used as a partitioning scheme in the QuickSort algorithm.
2. Memory Management:
- Memory Defragmentation: Applied in memory management systems to organize memory blocks of different types.
3. Image Processing:
- Pixel Sorting: Used in image processing where pixels need to be categorized into three distinct groups.
Understanding the Algorithm:
Let's understand this with a simple example where we need to sort an array containing only 0s, 1s, and 2s.
Step 1: Initialization of Pointers
- low pointer (low): Points to the leftmost position (index 0)
- Represents the boundary of the 0s section
- All elements before low are guaranteed to be 0s
- mid pointer (mid): Used for iteration (starts at index 0)
- Current element being examined
- All elements between low and mid-1 are guaranteed to be 1s
- high pointer (high): Points to the rightmost position (index n-1)
- Represents the boundary of the 2s section
- All elements after high are guaranteed to be 2s
Example array: [0, 1, 2, 0, 1, 2] Initial state: low = 0, mid = 0, high = 5
Step 2: Partitioning Process The array is divided into four sections:
- [0 to low-1]: Contains all 0s
- [low to mid-1]: Contains all 1s
- [mid to high]: Unknown/unsorted elements
- [high+1 to n-1]: Contains all 2s
Step 3: Sorting Process For each element arr[mid], we have three cases:
- When arr[mid] = 0:
- Swap arr[low] with arr[mid]
- Increment both low and mid
- This moves 0 to the left section
- Example: [0,1,2] → [0,1,2] (No change)
- When arr[mid] = 1:
- Leave element as is
- Just increment mid
- 1s naturally accumulate in middle
- Example: [0,1,2] → [0,1,2] (No change)
- When arr[mid] = 2:
- Swap arr[mid] with arr[high]
- Decrement high
- This moves 2 to the right section
- Example: [0,1,2] → [0,1,2]
Now Repeat the above steps for yourself as a practice - take reference from below images
Step 4: Termination
- Algorithm continues until mid pointer crosses high pointer
- At this point, array is fully partitioned:
- All 0s are at the beginning
- All 1s are in the middle
- All 2s are at the end
Example final state: [0,0,1,1,2,2]
Time and Space Complexity
- Time Complexity: O(n) - Single pass through array
- Space Complexity: O(1) - In-place sorting
- Stability: Not stable (relative order of equal elements may change)
Code
#include <iostream>
#include <vector>
using namespace std;
void dutchNationalFlag(vector<int>& arr) {
int low = 0;
int mid = 0;
int high = arr.size() - 1;
while (mid <= high) {
switch (arr[mid]) {
case 0:
swap(arr[low], arr[mid]);
low++;
mid++;
break;
case 1:
mid++;
break;
case 2:
swap(arr[mid], arr[high]);
high--;
break;
}
}
}
int main() {
vector<int> arr = {2, 0, 1, 2, 1, 0, 2, 1, 0};
cout << "Original array: ";
for (int num : arr) cout << num << " ";
dutchNationalFlag(arr);
cout << "\nSorted array: ";
for (int num : arr) cout << num << " ";
return 0;
}